Introduction to Lucenia
Lucenia is a distributed search and analytics engine that supports various use cases, from implementing a search box on a website to analyzing security data for threat detection. The term distributed means that you can run Lucenia on multiple computers. Search and analytics means that you can search and analyze your data once you ingest it into Lucenia. No matter your type of data, you can store and analyze it using Lucenia.
Document
A document is a unit that stores information (text or structured data). In Lucenia, documents are stored in JSON format.
You can think of a document in several ways:
- In a database of students, a document might represent one student.
- When you search for information, Lucenia returns documents related to your search.
- A document represents a row in a traditional database.
For example, in a school database, a document might represent one student and contain the following data.
| ID | Name | GPA | Graduation year |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
Here is what this document looks like in JSON format:
{
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
You'll learn about how document IDs are assigned in Indexing documents.
Index
An index is a collection of documents.
You can think of an index in several ways:
- In a database of students, an index represents all students in the database.
- When you search for information, you query data contained in an index.
- An index represents a database table in a traditional database.
For example, in a school database, an index might contain all students in the school.
| ID | Name | GPA | Graduation year |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
| 2 | Jonathan Powers | 3.85 | 2025 |
| 3 | Jane Doe | 3.52 | 2024 |
Clusters and nodes
Lucenia is designed to be a distributed search engine, meaning that it can run on one or more nodes---servers that store your data and process search requests. An Lucenia cluster is a collection of nodes.
You can run Lucenia locally on a laptop---its system requirements are minimal---but you can also scale a single cluster to hundreds of powerful machines in a data center.
In a single-node cluster, such as one deployed on a laptop, one machine has to perform every task: manage the state of the cluster, index and search data, and perform any preprocessing of data prior to indexing it. As a cluster grows, however, you can subdivide responsibilities. Nodes with fast disks and plenty of RAM might perform well when indexing and searching data, whereas a node with plenty of CPU power and a tiny disk could manage cluster state.
In each cluster, there is an elected cluster manager node, which orchestrates cluster-level operations, such as creating an index. Nodes communicate with each other, so if your request is routed to a node, that node sends requests to other nodes, gathers the nodes' responses, and returns the final response.
For more information about other node types, see Cluster formation.
Shards
Lucenia splits indexes into shards. Each shard stores a subset of all documents in an index, as shown in the following image.
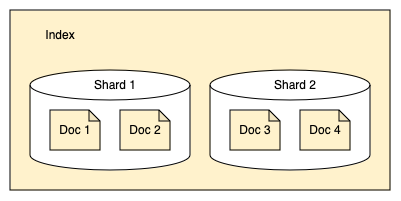
Shards are used for even distribution across nodes in a cluster. For example, a 400 GB index might be too large for any single node in your cluster to handle, but split into 10 shards of 40 GB each, Lucenia can distribute the shards across 10 nodes and manage each shard individually. Consider a cluster with 2 indexes: index 1 and index 2. Index 1 is split into 2 shards, and index 2 is split into 4 shards. The shards are distributed across nodes 1 and 2, as shown in the following image.
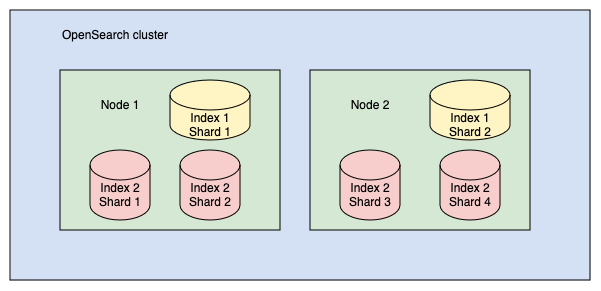
Despite being one piece of an Lucenia index, each shard is actually a full Lucene index. This detail is important because each instance of Lucene is a running process that consumes CPU and memory. More shards is not necessarily better. Splitting a 400 GB index into 1,000 shards, for example, would unnecessarily strain your cluster. A good rule of thumb is to limit shard size to 10--50 GB.
Primary and replica shards
In Lucenia, a shard may be either a primary (original) shard or a replica (copy) shard. By default, Lucenia creates a replica shard for each primary shard. Thus, if you split your index into 10 shards, Lucenia creates 10 replica shards. For example, consider the cluster described in the previous section. If you add 1 replica for each shard of each index in the cluster, your cluster will contain a total of 2 shards and 2 replicas for index 1 and 4 shards and 4 replicas for index 2, as shown in the following image.
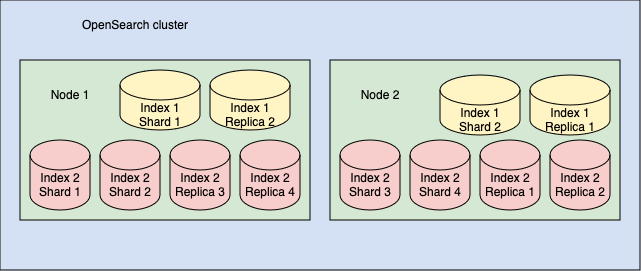
These replica shards act as backups in the event of a node failure---Lucenia distributes replica shards to different nodes than their corresponding primary shards---but they also improve the speed at which the cluster processes search requests. You might specify more than one replica per index for a search-heavy workload.
Inverted index
An Lucenia index uses a data structure called an inverted index. An inverted index maps words to the documents in which they occur. For example, consider an index containing the following two documents:
- Document 1: "Beauty is in the eye of the beholder"
- Document 2: "Beauty and the beast"
An inverted index for such an index maps the words to the documents in which they occur:
| Word | Document |
|---|---|
| beauty | 1, 2 |
| is | 1 |
| in | 1 |
| the | 1, 2 |
| eye | 1 |
| of | 1 |
| the | 1 |
| beholder | 1 |
| and | 2 |
| beast | 2 |
In addition to the document ID, Lucenia stores the position of the word within the document for running phrase queries, where words must appear next to each other.
Relevance
When you search for a document, Lucenia matches the words in the query to the words in the documents. For example, if you search the index described in the previous section for the word beauty, Lucenia will return documents 1 and 2. Each document is assigned a relevance score that tells you how well the document matched the query.
Individual words in a search query are called search terms. Each search term is scored according to the following rules:
-
A search term that occurs more frequently in a document will tend to be scored higher. A document about dogs that uses the word
dogmany times is likely more relevant than a document that contains the worddogfewer times. This is the term frequency component of the score. -
A search term that occurs in more documents will tend to be scored lower. A query for the terms
blueandaxolotlshould prefer documents that containaxolotlover the likely more common wordblue. This is the inverse document frequency component of the score. -
A match on a longer document should tend to be scored lower than a match on a shorter document. A document that contains a full dictionary would match on any word but is not very relevant to any particular word. This corresponds to the length normalization component of the score.
Lucenia uses the BM25 ranking algorithm to calculate document relevance scores and then returns the results sorted by relevance. To learn more, see Okapi BM25.
Advanced concepts
The following section describes more advanced Lucenia concepts.
Update lifecycle
The lifecycle of an update operation consists of the following steps:
- An update is received by a primary shard and is written to the shard's transaction log (translog). The translog is flushed to disk (followed by an fsync) before the update is acknowledged. This guarantees durability.
- The update is also passed to the Lucene index writer, which adds it to an in-memory buffer.
- On a refresh operation, the Lucene index writer flushes the in-memory buffers to disk (with each buffer becoming a new Lucene segment), and a new index reader is opened over the resulting segment files. The updates are now visible for search.
- On a flush operation, the shard fsyncs the Lucene segments. Because the segment files are a durable representation of the updates, the translog is no longer needed to provide durability, so the updates can be purged from the translog.
Translog
An indexing or bulk call responds when the documents have been written to the translog and the translog is flushed to disk, so the updates are durable. The updates will not be visible to search requests until after a refresh operation.
Refresh
Periodically, Lucenia performs a refresh operation, which writes the documents from the in-memory Lucene index to files. These files are not guaranteed to be durable because an fsync is not performed. A refresh makes documents available for search.
Flush
A flush operation persists the files to disk using fsync, ensuring durability. Flushing ensures that the data stored only in the translog is recorded in the Lucene index. Lucenia performs a flush as needed to ensure that the translog does not grow too large.
Merge
In Lucenia, a shard is a Lucene index, which consists of segments (or segment files). Segments store the indexed data and are immutable. Periodically, smaller segments are merged into larger ones. Merging reduces the overall number of segments on each shard, frees up disk space, and improves search performance. Eventually, segments reach a maximum size specified in the merge policy and are no longer merged into larger segments. The merge policy also specifies how often merges are performed.
Next steps
- Learn how to install Lucenia within minutes in Installation quickstart.